

M³BP

M³BPは、マルチコア環境でDAG形式で並列処理をするインメモリエンジンです。
小規模データでの複雑な処理を、単一ノード上のマルチコア用に最適化し、C++でネイティブアプリケーションで動作させて高速化しています。
最新のマシンは、CPUのコア数の増加・メモリの大容量化が進んでいるため、その資源を余すことなく利用します。
Asakusa Frameworkで開発したアプリケーションは、コンパイラでM³BP向けのC++プログラムに変換され、M³BP上で高速処理をします。1ノードで圧倒的な高速処理を実現いたします。
最速インメモリ実行エンジン
下表は同じ入力データサイズの業務データ処理を3実行環境で行った際のベンチマーク指標です。MapReduceの10倍、Sparkの2倍の速度でデータ処理を行います。マシンの台数は、MapReduce・Sparkは5ノードに対し、M³BPは1ノードとなり、5分の1の台数で処理を実施しています。従って、M³BPはMapReduceに対して50倍、Sparkに対しては10倍の費用対効果を示しています。1ノードで稼働しますので煩わしい運用も必要ありません。
処理時間延伸が課題となりやすい、基幹系バッチ処理に代表される小〜中規模の入力データサイズの処理をより高速化し、MapReduce,Sparkでの複数ノードCluster構築,運用の煩雑さによる障壁をまとめて解決いたします。

データ入出力も高速に
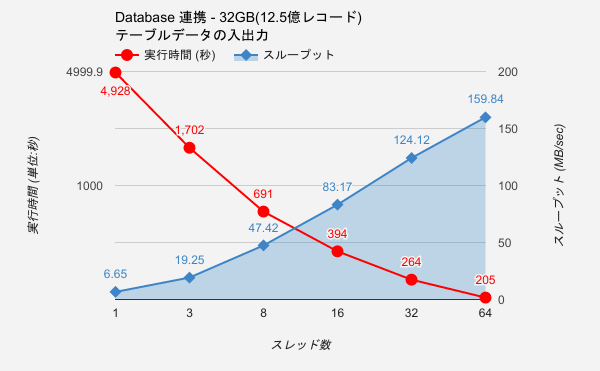
業務系バッチにおいては、入力データがRDBMSに格納されているケースも多いですが、データの外部入出力を行うコンポーネント WindGate の高速動作モード JDBCダイレクトモード ではAsakusa on M³BPがデータベースの入出力に利用する実行スレッド数やデータベースコネクション数などを実行環境に応じて適切に調整することが可能です。また、インメモリ上での展開となりDiskへの書出しも発生しないためデータ入出力も高速処理を実現しています。
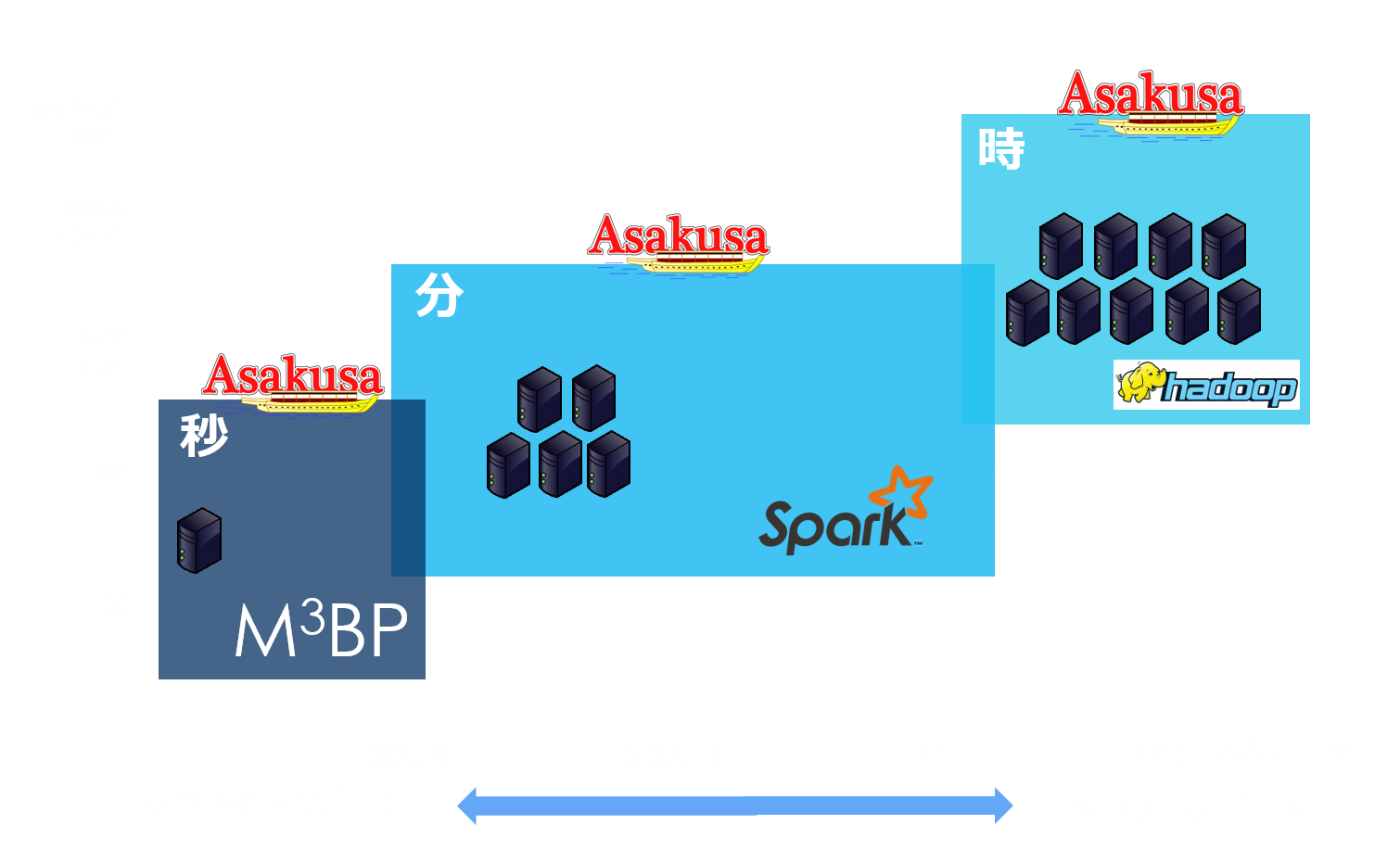
処理特性に応じた実行基盤の選択肢
バッチ処理に用いられる基幹系データのサイズは、多くのケースが実はあまり大きなサイズではありません。概ね100GB程度、50GB以下のケースも少なくありません。そのような比較的小~中規模入力データサイズの業務系バッチ高速処理に最適なエンジンがM³BPです。1ノードで稼働するので運用管理の煩わしさもありません。
更に、Asakusa Frameworkでプログラミングされたアプリケーションは、プログラムソースを一切変更することなくHadoop,Spark,M³BP どの実行基盤上でも稼働させることが可能です。システムライフサイクルの中で処理基盤に対する要件は変化しますが、Asakusa Frameworkならアプリケーション開発投資を保護しつつ、分散処理基盤それぞれの特性に応じたお客様の要件に最適な基盤選択が都度可能となります。
Asakusa on M³BPの技術情報
>技術情報はこちら
Asakusa on M³BPのホワイトペーパー
>ホワイトペーパーはこちら
M³ for BPのオープンソース公開情報
>M³ for BPのGitHubはこちら



