

分散処理/Asakusa Framework活用ケース
今まで処理時間やデータ量の制約で実現が難しかった加工,集計,分析といった処理が、分散基盤の高速処理性能で実現可能になっています。
月次でしか実行出来なかった分析・シミュレーション・確定処理・クレンジング 引当・受発注・在庫管理・予測などを日次や即時実行へ変更できるケースもあります。既存システムを分散処理に置換えるケースでは、概ね処理時間の桁が変わります。(xx時間がxx分へ)
また、データは集めたが活用には至っていない、やり方が良くないのか処理に時間がかかりすぎる、構造化/非構造化データの関連付けが難しく利用が進まない等、ビッグデータの利活用方法を模索する企業は今なお少なくありません。分散処理を用いれば処理時間やデータ量に起因する壁を乗り越えられ、経営に役立つインパクトがもたらされます。
代表的なユースケースが以下となります。
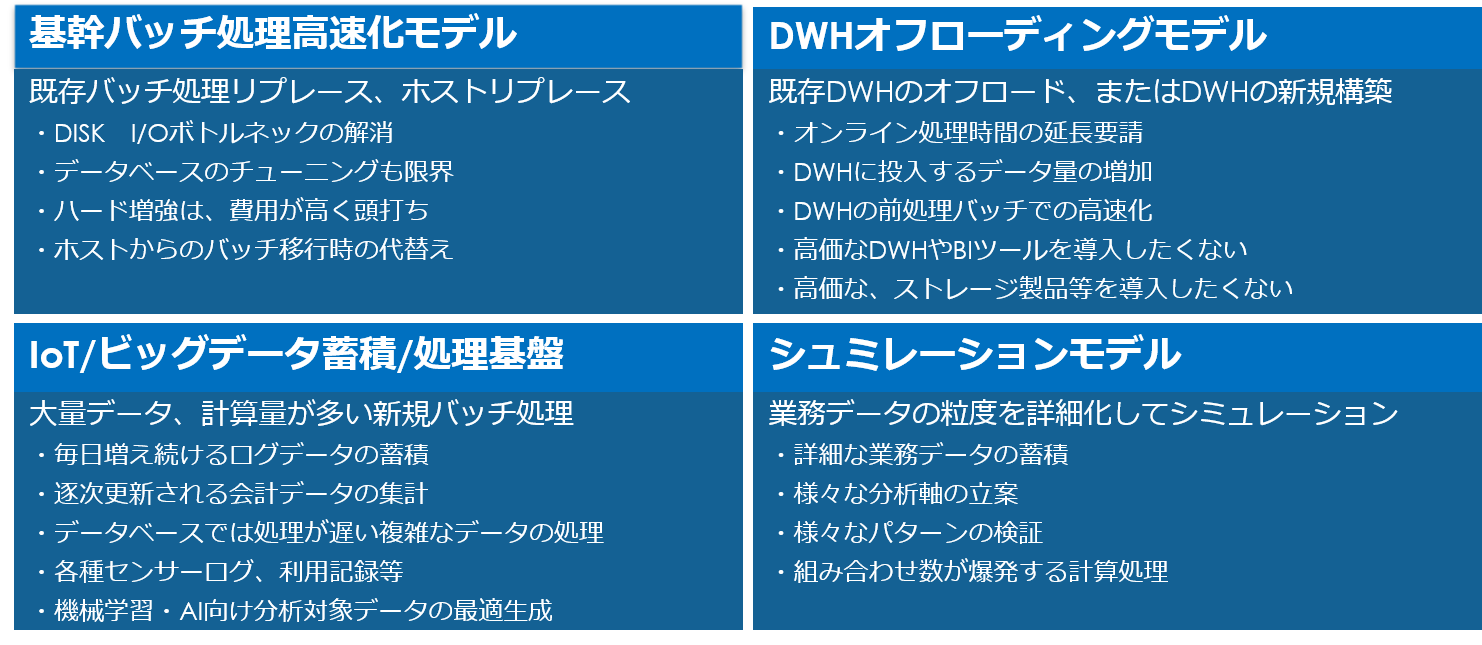
それぞれの詳細を以下に説明します。
- 基幹バッチ処理高速化
データ増に伴いバッチ処理時間は年々延伸化する傾向にあります。例えば、バッチが稼働するRDBMSのチューニングを繰返してきたがそろそろ限界に達する。ハードウェアのスケールアップ等増強にはコストがかさむ。メインフレームのCOBOLバッチ高速化に高額投資は行いづらい。
また、処理長時間化は運用コスト上昇につながります。バッチ処理失敗時のリトライを避けるため敢えて入力データを細切れにして処理を細分化し、人為的にチェックポイントを設けるといった、本来処理時間が早めれば必要のない運用工数が上積みされるケースも見受けられます。
そのような状況に対し、バッチアプリケーションを分散処理基盤へ置換えることにより高速化を図るのがこのモデルです。大半のケースで処理時間が xx時間 ⇒ xx分 と "桁" が変わるので単なる処理の高速化に留まらず大きなビジネスインパクトがもたらされます。
夜間実行前提のいわゆる夜間バッチ処理が業務時間内処理へ移行できるケースもあります。
- DWHオフローディング
データ分析の一般的な課題として、企業システムの"サイロ"化により分析対象データが散在しデータ連携も個別処理となるため、結果としてデータウェアハウス(DWH)がデータハブの役割を担い負荷が高まる要因となり、データ還元鮮度が悪化する傾向にあることがあげられます。
データは増えることはあっても減ることはありません。チューニングにも限界はあります。DWHアプライアンスは高価な製品が多く、ハードウェアスケールアップはコストがかさみます。
これらに対し本モデルでは、DWHでの加工、集計、バッチ処理やいわゆる前処理を分散処理基盤へオフロードすることで全体最適化を図ります。
加えて、データフローと分析処理を分離することで、データが揃うまでの時間短縮をももたらしますが、新たなインテグレーションは行わず既存データフローにバイパスを設けるだけなので大幅なシステムアーキテクチャの見直しは必要としません。
- IoT/ビッグデータ処理基盤
言うまでもなく分散処理の代名詞的なユースケースです。企業内データの統合格納基盤としてデータ蓄積の側面と、そのデータ処理を行う処理基盤としての側面を併せ持ちます。
最大の特徴の1つが、構造化/非構造化データをまとめて扱える点にあり、大量のIoT/ビッグデータ利活用を行うのには最適な基盤と言えます。機械学習,ディープラーニング向け分析対象データ生成用途での利用も増えています。
- シミュレーション
業務データの粒度を詳細化して行うシミュレーション処理に用いられるケースです。
粒度の細かい業務データの蓄積、様々な分析軸の立案、パターン変更行った際の検証、組合せ数が爆発する計算処理等、ひと昔前ならスーパーコンピュータを用いたような計算が現在では分散処理にて実現可能となっています。



