西鉄ストア様
新会計システム

既存の本部系システムは、老朽化が進行し、また旧来の機能では変化する業務への対応が困難で、全面的なリプレースが必要でした。特に新システムでは、オペレーションの水準をあげ業務生産性向上のための大幅な機能追加が求められ、データ処理の負荷が高まることが想定されおり、必要な処理性能の確保が重要なテーマの1つでした。
背景
- システム老朽化
- 処理データ増への対応(流通BMS*,新規出店etc)
- 変化する業務への柔軟な対応
- 業務生産性向上のための大幅な機能追加
- データサイズのわりに処理件数が圧倒的に多い
課題
- 追加業務機能による粒度の細かいデータ処理
- 計算量が膨大となる
- 基幹系から情報系へのバッチ処理が遅い
- 継続的な業務深化が予定されており、システム負荷増も見込まれたため効率的なパフォーマンス/可用性の確保が必要
ソリューション
Hadoop*とクラウドの採用
跳ね上がる計算量に必要な処理性能はHadoop*で確保し、その後の継続的な業務深化に伴う効率的なシステム稼働についてはクラウドへの移行でパフォーマンス/可用性を確保。
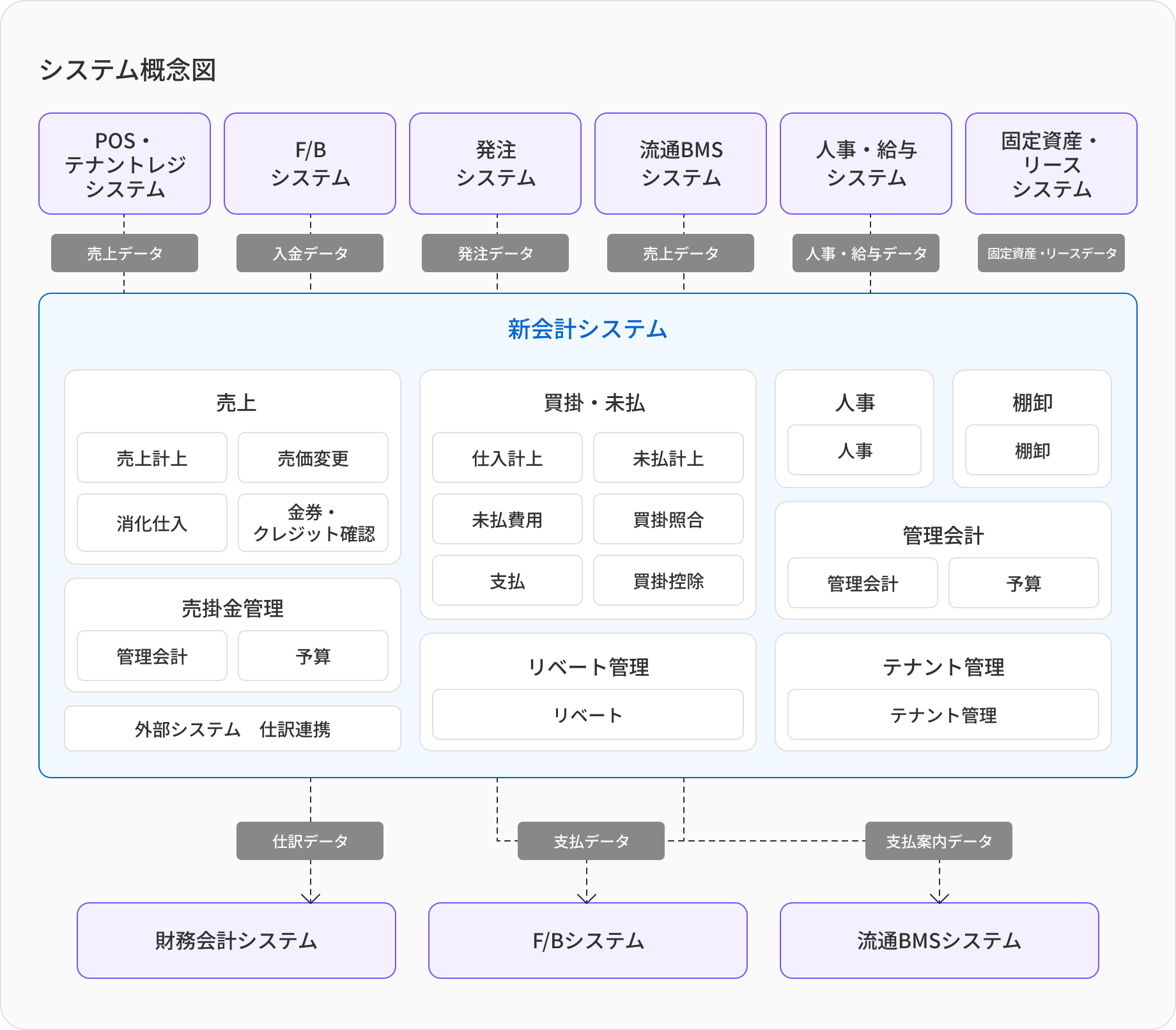
システム機能 (導入時点 2013年)
売上:最大で1億件/dayの 締め処理
債権管理:900万件程度の集計処理
仕入:2700万件の取り込みクレンジング処理
債務処理:日別で300万件のマッチング処理
データサイズ
100GB〜500GB
バッチ処理時間
トータル 8時間
AWS*上で24h365dの運用 2013年から本番稼動
運用・監視・バックアップ・リストアも弊社で実施
新システムで実現した代表的な処理
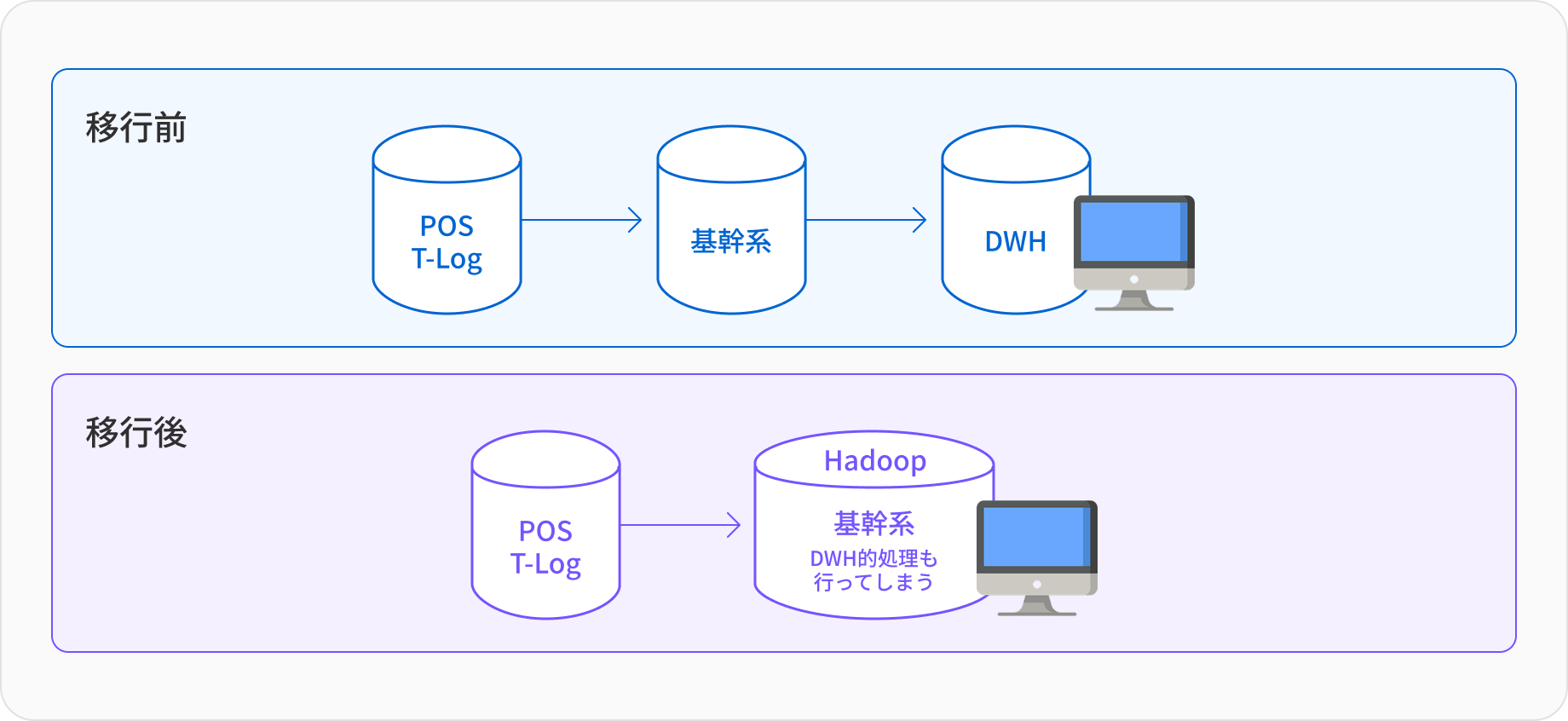
売上計上処理
従来の売上計上処理は、基幹系の締め処理であり情報系とは分離されていた
・基幹系から情報系に渡すバッチ処理が遅すぎる
⇓ ⇓ ⇓
基幹系と情報系の流れを統合することにより「基幹系のデータ」をあたかも情報系のデータのように参照する
・確定基幹データをそのまま利用する
・データの不整合が発生しない
・業務系では本来アドホック分析は必要ない
・圧倒的なバッチ処理能力が必要
Hadoop*の高処理能力
仕入処理
支払確定処理
・従来は計上ベースでのみ支払確定処理を実施。請求データとの付合せは行わず
・請求データとの付合せは伝票明細行単位での処理になるため処理コストが非常に高い
・決済は日次ではなく月次で3回処理なのでバッチコストが高い
・オープンな明細を「すべて」取り込む必要がある (毎回4-5千万件の明細フルマッチング)
⇓ ⇓ ⇓
請求データを電子的に処理することが可能となり、電子データ自体を取り込んで物流からの検収確定データとライン・バイ・ラインでの突合を行うことで正確な決済を実現
Hadoop*の高処理能力による
効果
- 新システムで求められた高処理要件はHadoop*(分散処理)で解決
- 出来なかった,あきらめていた処理を実現
- 業務深化に伴う継続的なパフォーマンス/可用性はクラウド利用で確保
- 業務生産性の大幅な向上
導入後5年経過したシステム状況
2018年時点の新会計システムの状況
- HadoopからM³BPへプラットフォームを変更
- AsakusaFrameworkのポータビリティ機能により、コード変更無しでアプリケーションを移行
- パフォーマンスは大幅に向上
13時間 → 5~6時間
(*導入時点2013年のバッチ処理トータル8時間が5年間で13時間へ延伸)
- アマゾン ウェブ サービス、AWS、Amazon Web Service、Amazon EC2、Amazon VPC、Amazon S3およびAmazon Web Services ロゴはAmazon.com, Inc.または、その関連会社の商標です。
- 流通BMSは、財団法人流通システム開発センターの登録商標です。
- Hadoopは、Apache Software Foundationの登録商標です。
- 本記事に記載されている製品名などの固有名詞は、各社の商標または登録商標です。