

システム開発の特長
スケールアウト可能なデータ設計
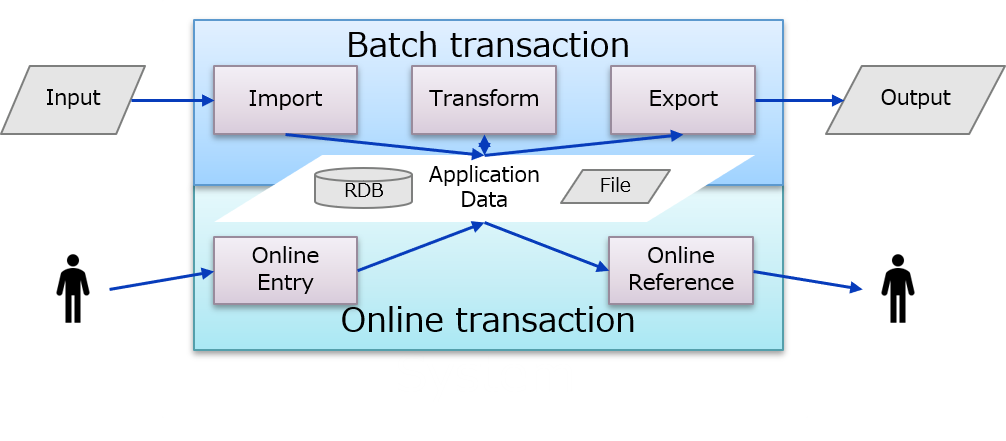 ■システムの基本は外部とのデータ入出力(Input/ Output)、画面操作などによる登録、参照(Online Entry/Referrence)及びバッチ処理によるデータの抽出・変換処理(Transform)で構成されています。
■システムの基本は外部とのデータ入出力(Input/ Output)、画面操作などによる登録、参照(Online Entry/Referrence)及びバッチ処理によるデータの抽出・変換処理(Transform)で構成されています。
■システムで発生するボトルネックの多くは (1)大量データのバッチ処理(抽出、変換、集計など) (2)トランザクション競合 の2つのケースで発生しています。
■(1)大量データ処理 はデータ量に対して選択した実装形式の限界に達している可能性があります。解決には並列化、分散化など他の実装方式を検討する必要があります。
別の原因としてはデータモデルに対し非効率なアクセスとなっている可能性があります。これは業務要件により様々な視点からアクセスする必要があるため非効率となってしまう可能性です。この場合にも並列化、分散化は有効ですがデータモデルの変更により改善される可能性もあります。
■(2)トランザクション競合 は主に異なるユースケース間でのデータ競合にて発生します。競合が業務上不可避であるのかを見極める必要があります。不可避な競合ではアーキテクチャ、インフラを含めた検討が必要となります。
■ボトルネックを解消する手段として並列化、分散化は非常に有効です。Webシステムでの大量アクセスはフロントサーバのスケールアウトにより並列化し性能を向上させることは一般的ですが、バッチ処理ではサーバのスケールアップによる対処がほとんどです。これは多くのシステムが データモデルのエンティティ=RDBのテーブル として設計、実装してきたことに起因します。このため性能向上にはスケールアップやDWHへの移行といった手段しかありませんでした。
バッチ処理性能向上のための解決手法の提供
 ■基幹システムにおけるバッチ処理は取引など基幹業務に直結するケースも多く、予定時刻に完了することは大変重要です。大量データのバッチ処理では並列化により全体スループットの向上が期待できます。
■基幹システムにおけるバッチ処理は取引など基幹業務に直結するケースも多く、予定時刻に完了することは大変重要です。大量データのバッチ処理では並列化により全体スループットの向上が期待できます。
■Javaではスレッド処理のライブラリ利用により業務ロジックの並行化が可能です。しかし並行処理されるデータの分割や制御は各アプリケーションごとに実装する必要があるため難易度が高く、保守性も低下します。また、単一ノードでの実行なのでスレッド数の上限はマシン性能に依存するため、更なる性能向上には実行マシンのスケールアップが必要となります。
■分散化による並列化ではノード増設により性能を向上できるためデータ増加時の対応が容易であり、単一ノードでは不可能であった大量データの処理を可能とします。Hadoop*(MapReduce*)やSpark*のクラスタ環境で実行することにより大容量データの処理を可能とします。ただ、Hadoop*、Spark*を利用するアプリケーションの互換性はないためそれぞれ個別に開発する必要があります。
■AsakusaFrameworkで実装されたコードは書き換えなしにHadoop*用、Spark*用のモジュールをビルド可能です。また、これらモジュールは容易にAWS*のEMR*でも実行可能です。
■さらにM³BPはメニーCPUコアの単一ノードインメモリ実行エンジンです。メニーCPUコアマシン内で並列処理を行うためマシンスペックによる限界はありますが最速で処理が可能です。
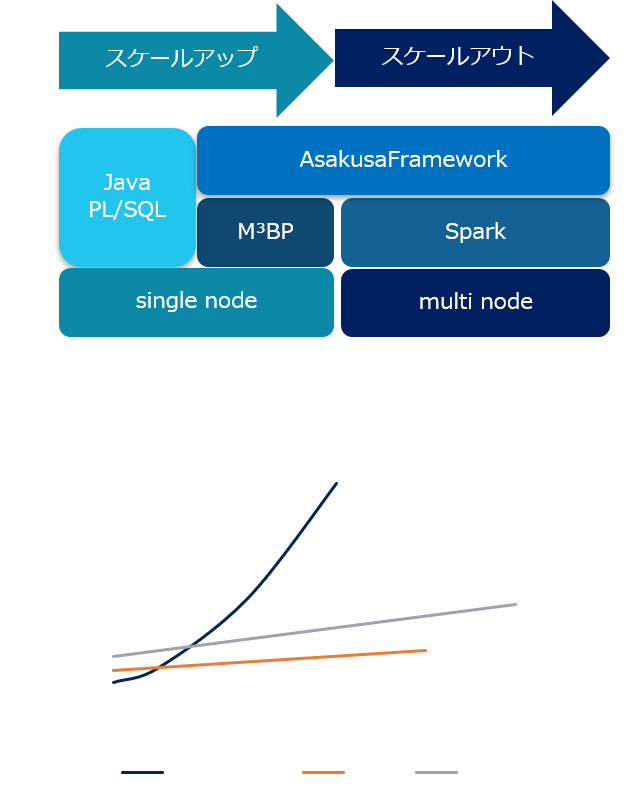
■右図グラフはデータ量と処理時間の関係を処理方式ごとに示したイメージ図です。RDBのみで処理を行う場合、データ量が一定規模までは最速に処理可能ですがデータ量が増えるに従い指数関数的に処理時間が増大します。一方、分散処理ではデータ増加に対する処理時間はリニアに推移します。M³BPではマシンスペックの限界までですが、分散クラスタ(Hadoop*、Spark*)では更に大容量のデータ処理が可能です。
■ノーチラス・テクノロジーズでは現在および将来のデータ量と許容する処理時間、コスト、保守運用などを考慮し最適なソリューションを提供します。
非機能設計と運用
■インフラ設計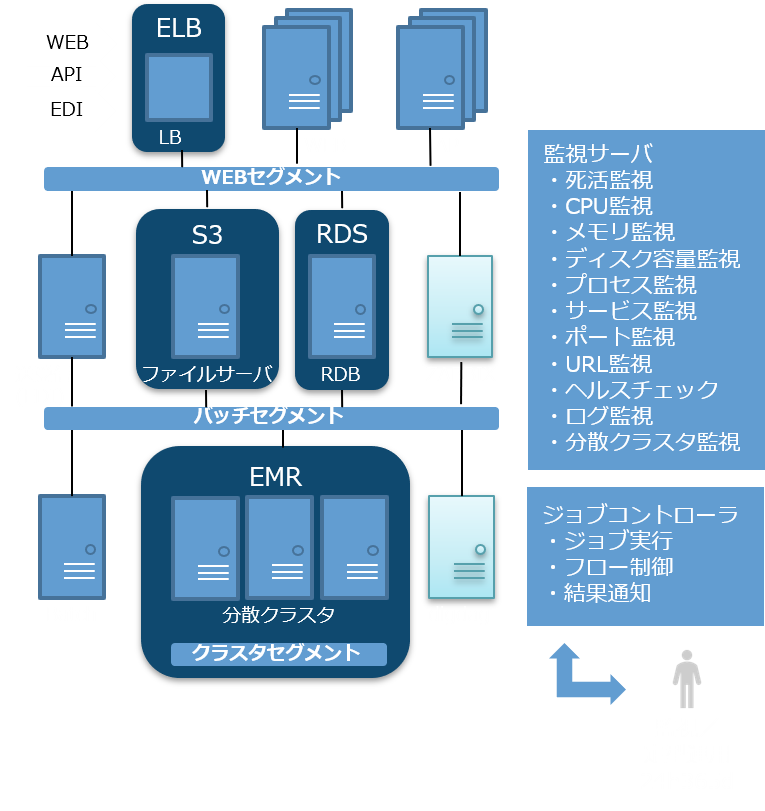
基幹システムでは安定して稼働するためのインフラ構築が重要です。非機能要件にて定義された可用性、性能・拡張性、運用・保守性、セキュリティに基づいてH/W、N/Wの構成を設計を行います。
■クラウドサービスの利用
システム全体または一部をクラウドにて稼働させるケースではクラウドサービスの利用も有効な手段です。右図の紺色で囲まれた4箇所はAWS*を例とした同等のサービスであり、要件により利用することが可能です。
■運用設計
– 運用設計は正常時の効率的な稼働計画に加えて、障害時のリカバリについても十分な検討が必要です。障害発生を未然に防ぐ仕組みに加え、機器の故障、連携先のデータ欠損や未受信など様々なケースを想定したリカバリ手順の設計が重要です。
– 従来のオンプレミス環境に比べ、クラウド利用や複数のデータ基盤(ファイル、RDB、HDFS)、処理基盤(分散クラスタなど)を利用したシステムではそれぞれの特性を考慮した設計が必要となります。
■運用支援
– 弊社では多くのシステムでZABBIX*、digdag*を監視,ジョブコントローラに利用しています。これらから通報される障害検知、異常終了等のアラートにより手順に従ったリカバリを実施します。
– クラウド環境やRDB,分散クラスタ利用のハイブリッド基盤では、それぞれのサービスに関する技術習得が必要ですが、弊社では分散技術、クラウド利用や運用支援の豊富な実績に基づいた運用サービスを24h365dで提供いたします。
クラウドの利用
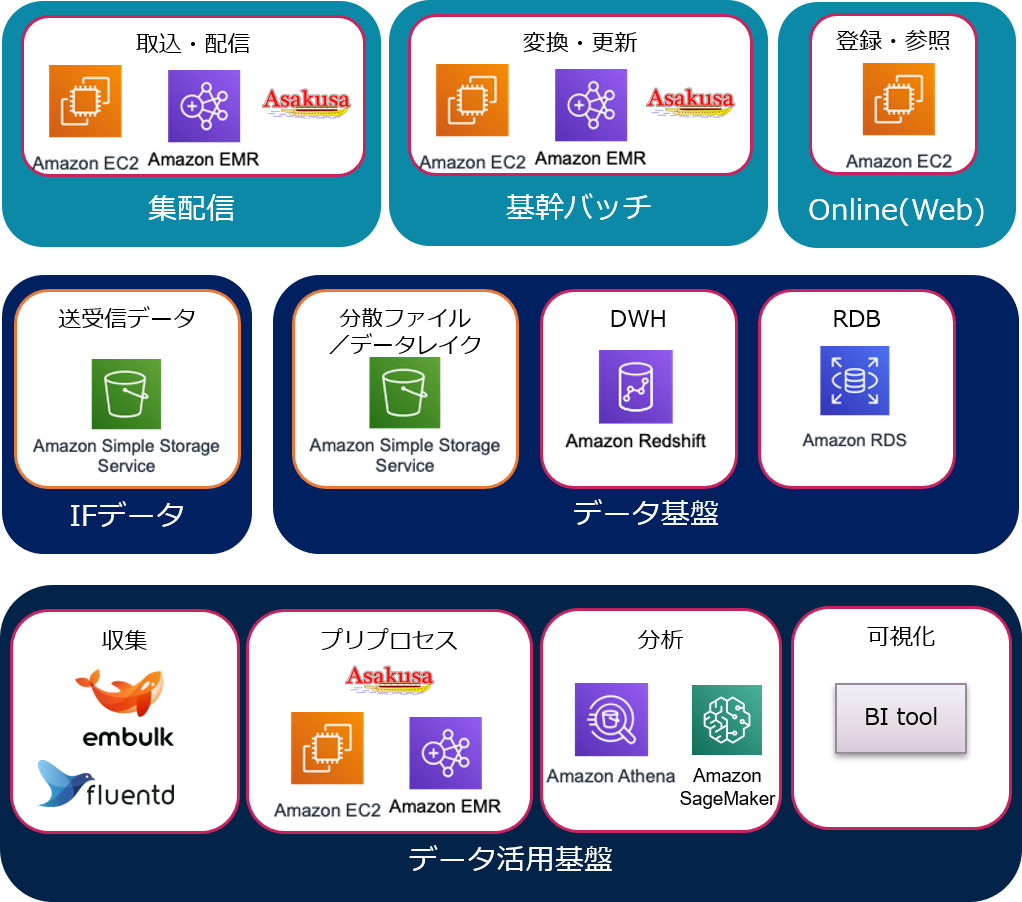 ■様々なシーンでのクラウド活用
■様々なシーンでのクラウド活用
クラウドサービス、OSSの利用により生産性、コストパフォーマンスを向上させ、短期間でデリバリー可能なシステム構築を提供します。基幹業務、データ活用基盤においてクラウドサービス、OSS、AsakusaFrameworkを利用しデータを処理します。
■特性に応じたHybridデータ基盤
–データ基盤はデータサイズやユースケースなど特性により最適な格納方式を利用します。大規模データ、分散処理に適したファイルやオンライン処理向きのRDBなどクラウドのマネージドサービスが利用可能です。
–これらのデータ処理は仮想サーバ(EC2*)や分散クラスタ(EMR*)にて実行します。AsakusaFrameworkアプリケーションではどちらの処理方式でも実行可能です。
■データ分析とのスムーズな連携
–クラウドに構築されたデータ活用基盤ではクラウドが提供する様々なサービスを利用することでスムーズなデータ連携が可能となります。
一般的なシステム開発との違い

*アマゾン ウェブ サービス、AWS、Amazon Web Service、Amazon EC2、Amazon VPC、Amazon S3およびAmazon Web Services ロゴはAmazon.com, Inc.または、その関連会社の商標です。
*ZABBIXはZabbix LLCの登録商標です。
*digdagはTreasure Data,Inc.の登録商標です。
*Hadoop,Sparkは、Apache Software Foundationの登録商標です。
*本記事に記載されている製品名などの固有名詞は、各社の商標または登録商標です。



